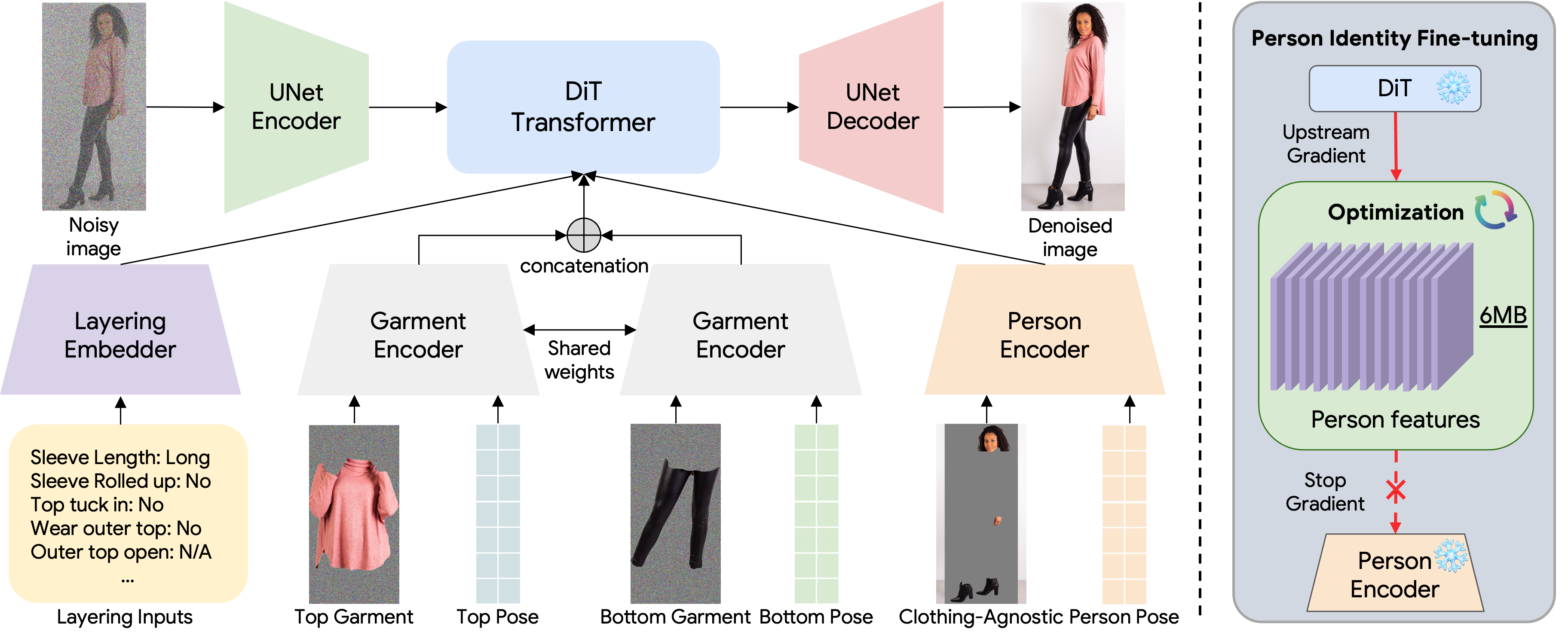
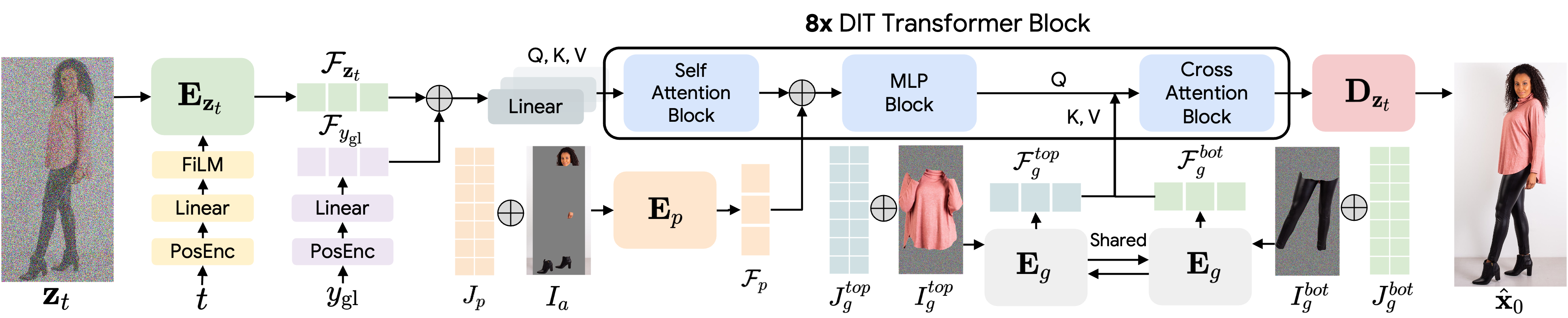

























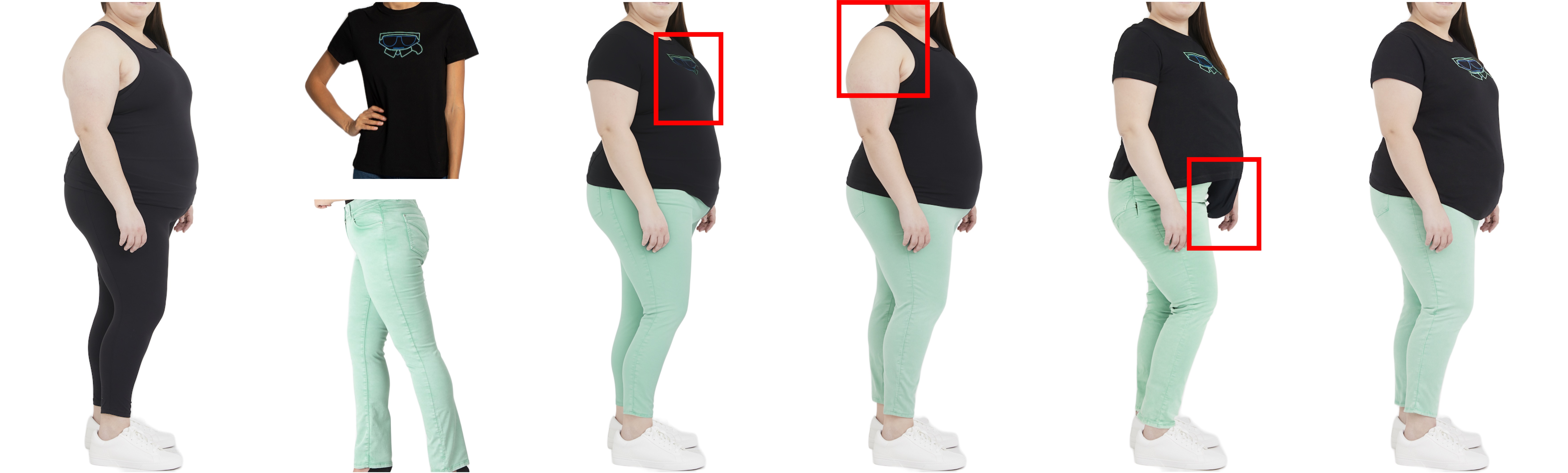


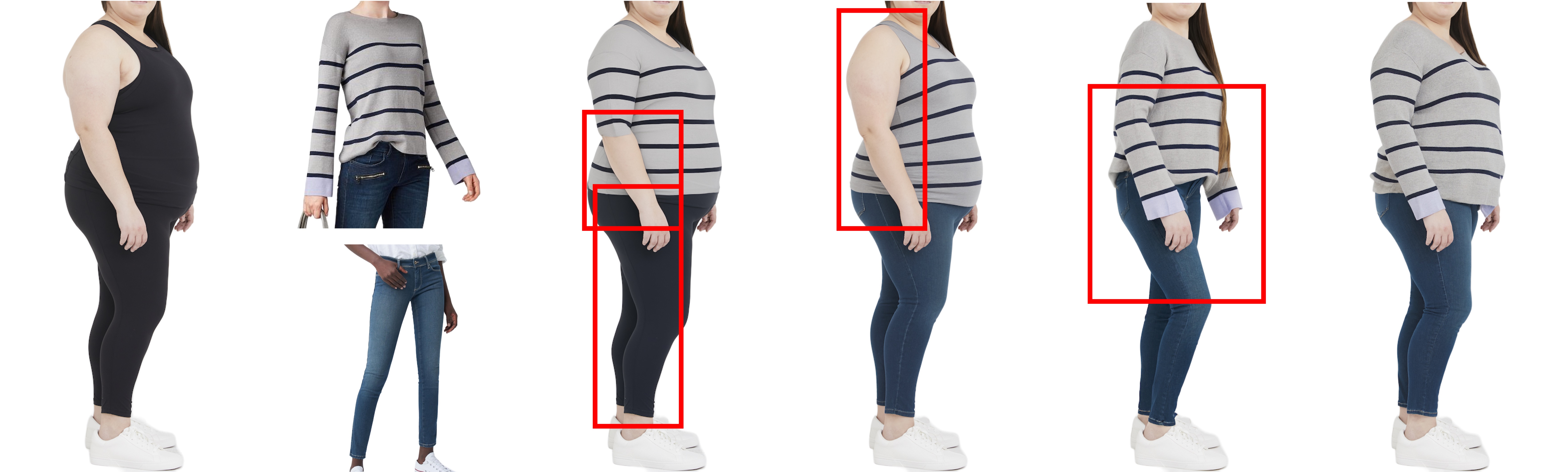
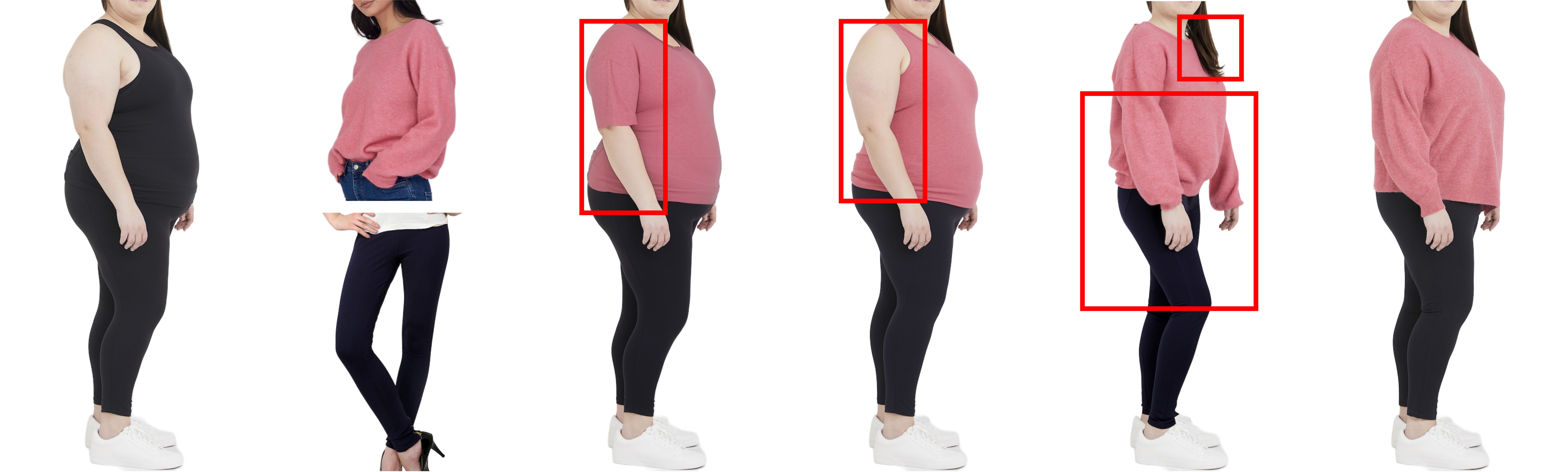


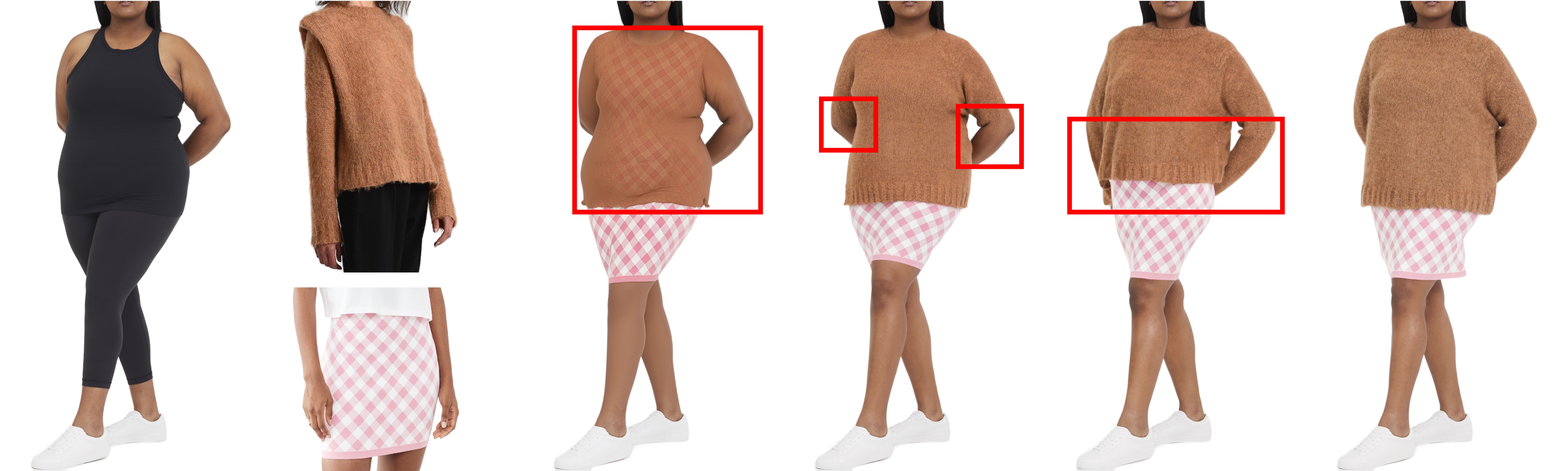

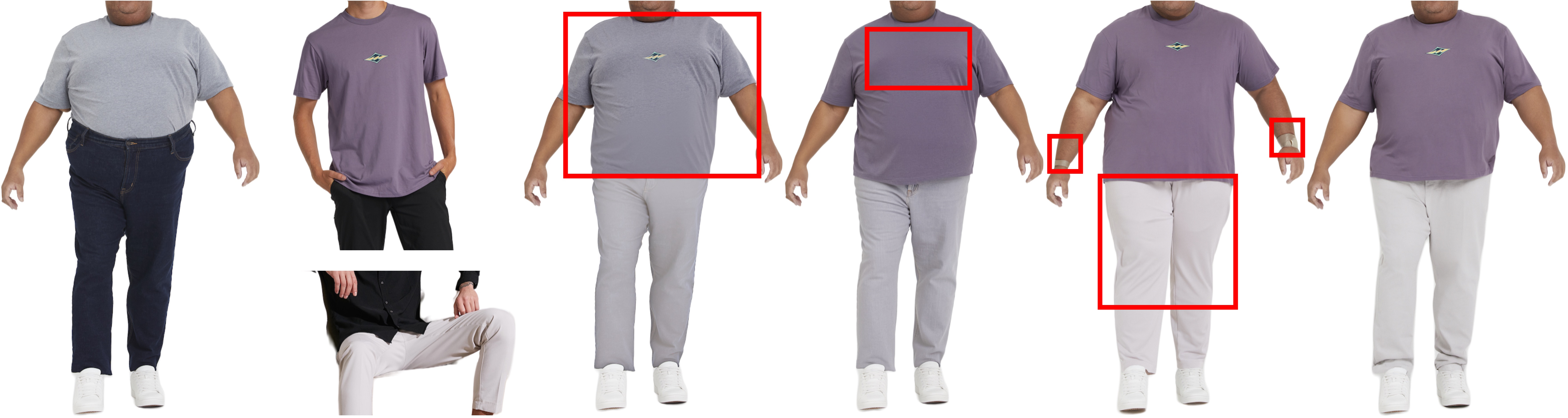

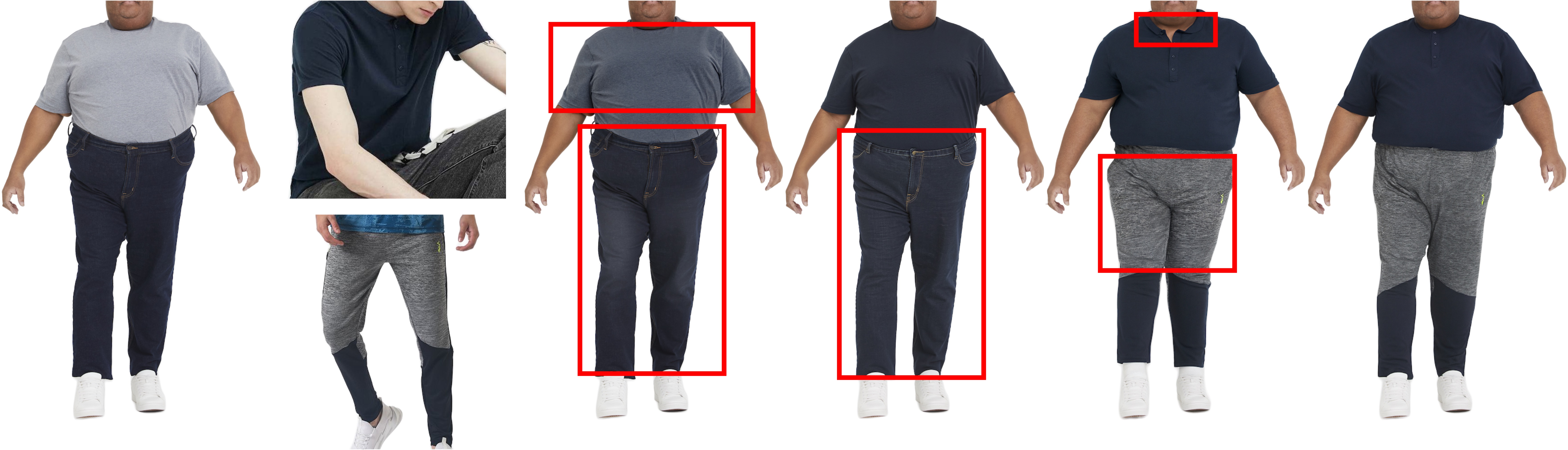


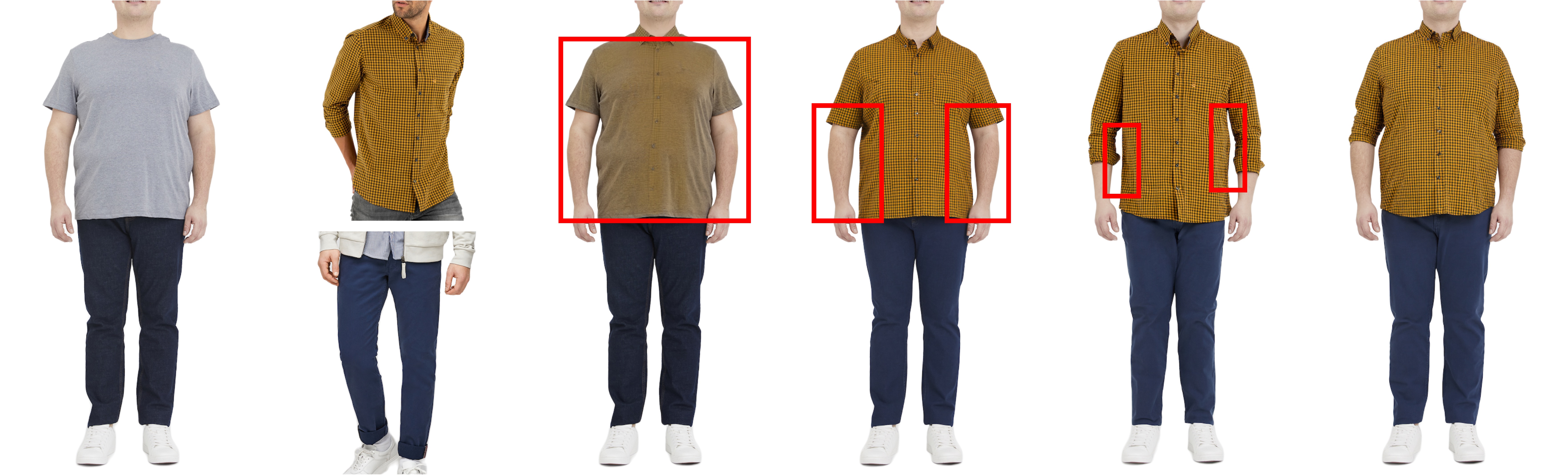


































BibTex
@InProceedings{Zhu_2024_CVPR_mmvto,
author={Zhu, Luyang and Li, Yingwei and Liu, Nan and Peng, Hao and Yang, Dawei and Kemelmacher-Shlizerman, Ira},
title={M&M VTO: Multi-Garment Virtual Try-On and Editing},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year={2024},
}
Special Thanks
This work was done when all authors were at Google. We would like to thank Chris Lee, Andreas Lugmayr, Innfarn Yoo, Chunhui Gu, Alan Yang, Varsha Ramakrishnan, Tyler Zhu, Srivatsan Varadharajan, Yasamin Jafarian and Ricardo Martin-Brualla for their insightful discussions. We are grateful for the kind support of the whole Google ARML Commerce organization. We thank Aurelia Di for her professional assistance on the garment layering Q&A survey design.